코드스테이츠 수강 7주차 2일차에는 코딩테스트 준비를 위한 대표적 유형(대표적 알고리즘)을 일부 배웟다.
1. 알고리즘?
우리가 특정 목적을 갖는 코드를 작성 할때, 사실 내가 짠 코드만 정답인 것이 아니다.
뭐든지 서울로만 닿으면 그만인데, 이게 방식에 따라 더 빨리가느냐, 늦게 가느냐 차이가 있는 것이다.
그런데, 기왕이면 좀 빨리 서울 가고, 비용도 적게드는 방법이 좋지 않을까?
그래서 알고리즘 공부가 필요하다.
실제로 서버에서 데이터를 다룰 때 굉장히 많은 데이터를 다루므로 최대한 많은 것을 빠르게 처리하는것이 궁극적인 목표이기 때문에 단순 구현 뿐 아니라 "어떻게" 데이터를 다루어야 하는지 정해야 한다.
쉽게 말하면 알고리즘은 "데이터를 다루는 방식"이라고 보면된다.
다행히, 선배 개발자들은 어떤방식으로 어떤식으로 적용해야 하는지 개념들을 잘 정리 해 놓았다. 우리는 그것에 맞게 공부해서, 적절히 사용하면 된다.
2. 의사코드
우리(내가)가 코드를 짤때, 일단 뭘 어떤식으로 구성해야 하는지 생각을 하고 코드를 짜게된다.
그런데, 이게 코드를 짜다보면 아까 썻던 변수를 또 가져오고 또 쓰고 데이터를 이캐캐 아주 들들볶는데, 이게 자꾸 헷갈리니까 주석으로 메모해놓곤 한다.
이제는 알고리즘이나 구현 등의 코드 길이가 길거나 고려해야 할 사항이 많아지기 때문에 의사코드는 반 이상, 아니 거의 필수다.
의사코드는 양식이 없다, 하지만 적어도 자기 자신만큼은 제대로 알 수 있게 "뼈대"를 만드는 작업이라고 생각하고 꼭 코드를 작성하기 전에 의사코드로 대략적인 개념은 잡고 코딩하자.
만약, 1~10까지 더하는 코드를 쓴다고 하면 나라면 이렇게 주석으로 쓰고 시작한다.
// 1~10까지 담은 int형 배열 만듦
//담는 값 저장하는 변수 sum을 만듦
// for문으로 10번 돌리는 세팅 만듦
// for문 돌면서 배열에 저장된 수를 sum에 하나하나 더함
// for문 10번 다 돌면 sum을 출력
간단히 어떤 변수를 만들고, 뭘 저장할 지, 어떤 문법 구문으로 구현 하고 몇번 반복하면 좋을지 써놓는게 빈 공간에 코드를 쓸때 적어도 막연한 느낌은 없애 줄 수 있다.
"굳이 이런거를 블로그 글로 손아프게 썻냐" 할 수 있는데.
안쓸때는 몰랏는데, 먼저 의사코드를 쓰고 코드 작성을 시작하면 적어도 시작하는게 어렵지 않다.
빈 공간에, 껌뻑이는 커서 하나만 있는 상태에서 원하는 기능을 뚝딱 만드는게, 아무것도 없는곳에서 바로 "시작"하는게 제일 어려운 것 같다.
이제 알고리즘도 배우고, 구현도 하면 코드를 줄줄줄 써야 한다. 의사코드 쓰자
3. 시간복잡도(Time Complexity)
종종 코딩문제를 풀때, for문으로 풀때는 덜한데, while문으로 풀 때 "출력 나오는데 생각보다 오래걸리네" 하는 경험이 있을 것이다.
컴퓨터는 기본적으로 연산하는 놈인데, 연산 횟수가 많으면 자연히 오래걸린다.
우리는 이럴때 자연스럽게 "이거 생각보다 오래걸리는데, 더 빨리하게 못하나?" 하는 생각을 할 때가 많다.
시간 복잡도는 이러한 생각을 수치적으로 나타내는 지표 라고 볼 수 있다.
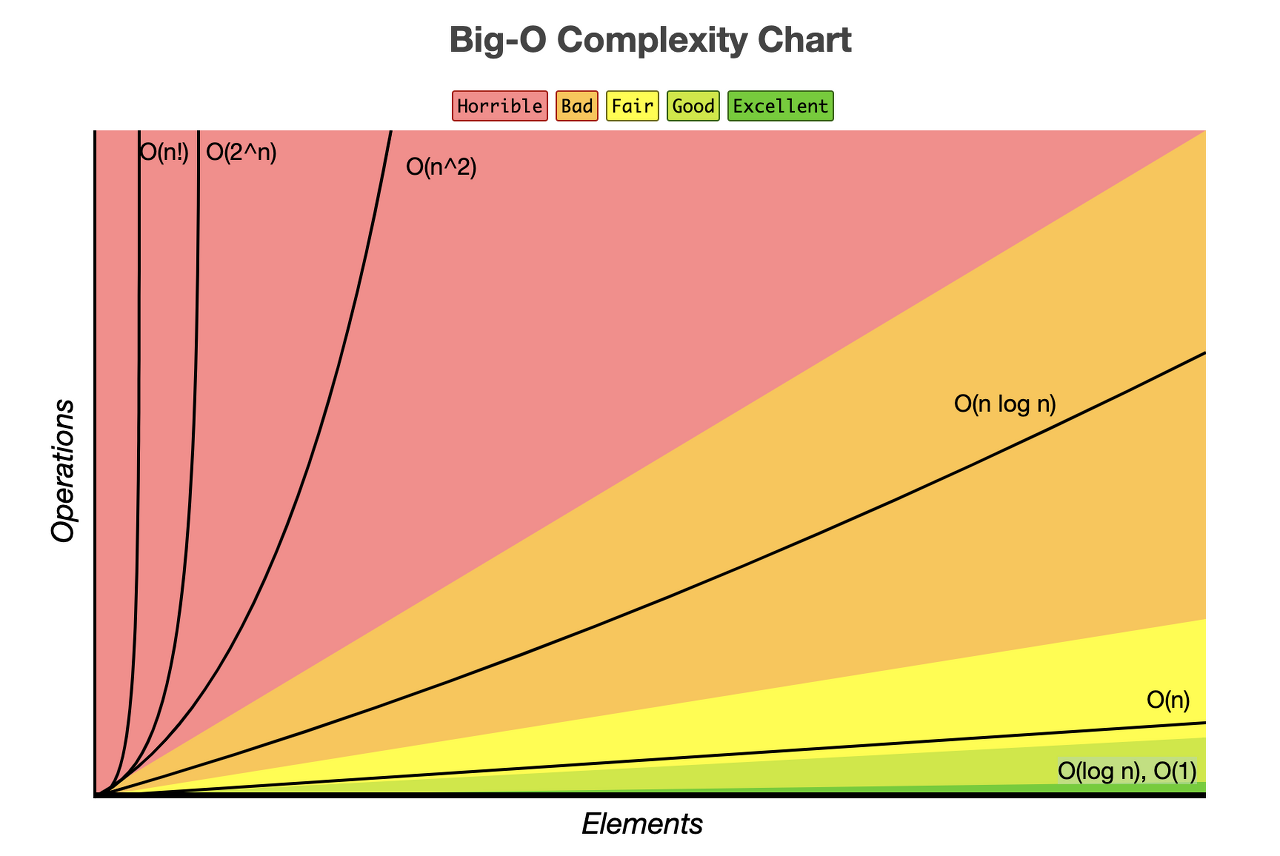
Big-O 표기법
일단, 위의 그림을 보면 우리가 학창시절에 배웟던 익숙한 그래프가 보인다.
일단 시간 복잡도는 "입력값의 변화에 따라 연산을 실행 했을 때, 연산횟수에 비해 시간이 얼마나 걸리는가"를 수치적으로 나타내는 것이다.
그래서, 코드의 연산방식에 따라 연산할 데이터가 많아지면 기하급수적으로 시간이 늘어나거나, 혹은 처리되는 속도가 일정하거나, 다른 방식에 비해 더 적게 시간이 들어가는 경우도 있다.
그런데 들어가는 데이터에 따라 같은 코드라도 다른 연산시간이 나타날 수 있다. 그래서 Big-O 표기를 한다.
- Big-O : 해당 코드를 실행 했을 때 가장 오래걸리는 경우 (최악)
- Big-Ω : 해당 코드를 실행 했을 때 가장 빨리 결과를 내는 경우 (최선)
- Big-θ : 해당 코드를 실행 했을 때 평균적으로 실행되는 시간 (평균)
우리는 이 코드에 뭐가 들어갈지, 얼마나 들어갈지 모르니 항상 최악을 기준으로 코드를 작성해야 한다.
(업무보고 할때 항상 일정에 마진을 주고 최악의 경우만 따졋을때 기준으로 일정을 조율하는것과 같다. ㅎ)
1. O(1)
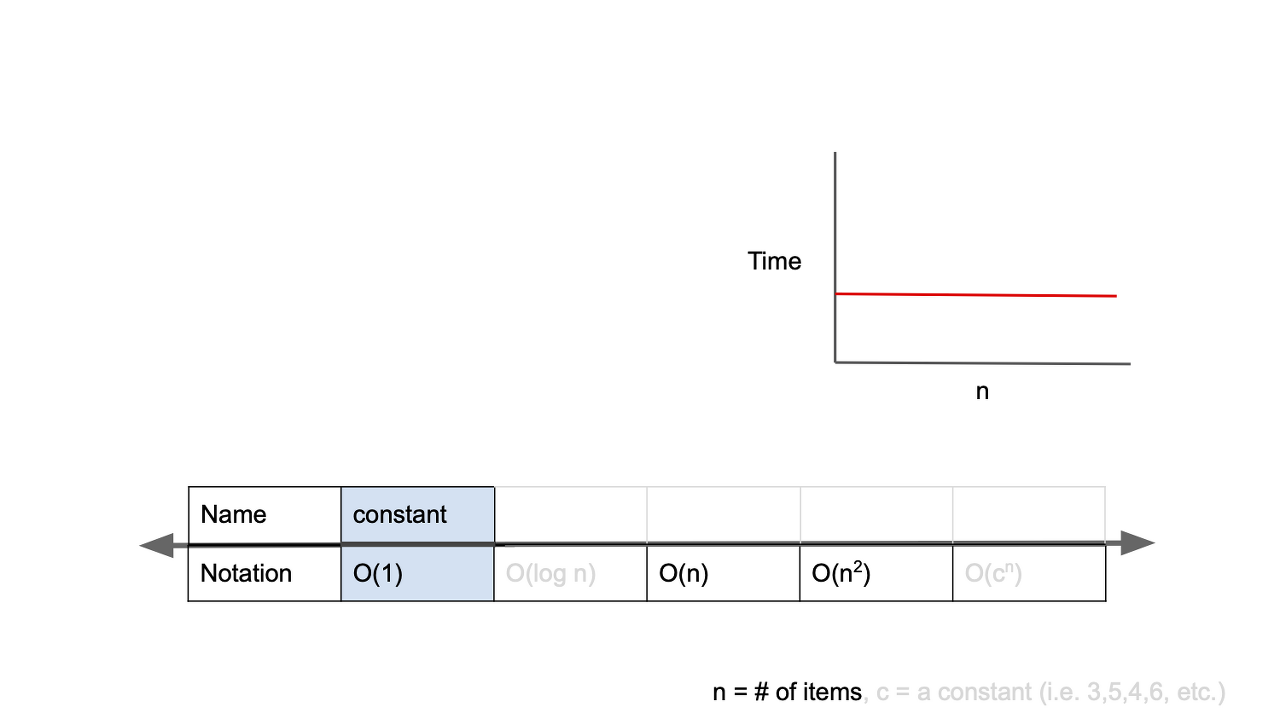
시간복잡도 O(1) 를 가지는 알고리즘은 입력에 따라 항상 균일한 연산속도를 보인다는 특징을 가진다.
입력값이 증가하더라도 출력되는 시간이 늘어나지 않는다. -> 입력값의 크기와 관계 없이 즉시 출력값이 나온다!
O(1) 를 가지는 코드 예시
public int O_1_algorithm(int[] arr, int index) {
return arr[index];
}
int[] arr = new int[]{1,2,3,4,5};
int index = 1;
int results = O_1_algorithm(arr, index);
System.out.println(results); // 2단순히 배열에서 인덱스에 해당하는 출력을 꺼내는 코드이므로, 입력값을 크기와 관계없이 항상 일정한 시간이 걸린다.
2. O(n)

O(n)은 입력값이 증가하면 출력값도 비례해서 늘어나는 경우다.
만약 1부터 들어온 숫자 N까지 순서대로 출력하는 코드를 작성한다고 하자, 숫자가 하나 나오는데 1초가 걸린다고 치면
N 이 5로 들어오면 -> 5초
N이 10으로 들어오면 -> 10초
....
N이 100으로 들어오면 -> 100초
N의 크기에 비례해서 출력되는 시간이 달라지는 것이다.
코드 예시
public void O_To_N(int n) {
for(int i = 0; i <= n; i++) {
System.out.println(i);
}
}그런데 주의할점은, 이렇게 일차함수 처럼 시간이 늘어나기만 하면 O(n)이라고 한다는 것이다.
public void O_To_N(int n) {
for(int i = 0; i < n * 2; i++) {
System.out.println(i);
}
}위의 코드는 n에 2배씩 늘어나게 된다.
n에 5가 들어가면 -> 10초
n에 10이 들어가면 -> 20초
.....
"앞선 코드보다 2배 늘어나니까 O(2n)이네!" 할 수도 있다.
하지만, 위 코드, 아래 코드 둘 다 입력값이 커질수록 O(n)의 n 앞에 붙는 수의 이미가 없어진다 (n이 계속 커져서 무한대에 가까우면 결국 둘다 무한대니까 라고 슬쩍 넘어가자)
고로, 두 코드 모두 O(n)으로 표기한다.
3. O(log n)

O(log n)은 쉽게 말해서 연산을 할 수록 시간이 줄어든다고 보면 된다.
앞서 설명한 O(1)다음으로 빠른 시간복잡도인데, 사실 값을 조회하는것 이외에 뭔가를 계산해서 도출해내야 하는경우 이 시간 복잡도를 목표로 코딩하는것이 가장 바람직하다.
(사실, 잘 안된다 ㅎ)
O(log n)의 경우 가장 적절한 예시가 이진탐색이다.
이진탐색은 왼쪽노드에 부모노드보다 작은 값을, 오른쪽 노드에 부모보다 큰 수를 배치하면서 이진 트리를 만들고, 거기서 답을 찾는 것과 비슷하다.
뭔말이냐고?
그냥 연산할때마다 연산해야 하는 데이터 수가 반으로 줄어든다고 생각하면 된다.
만약 나이 알아맞히기 업 다운 게임을 한다고 하자. (가장 대표적인 예시이다.)
- 1~100 중(사람 나이니까) 임의의 숫자 (나이, 30세로 지정)을 구한다고 하자
- 일단 50업인지 다운인지 물어보면 , 30은 50 보다 작으니, 다운 -> 1~100 에서 1~50으로 범위가 줄어듦
- 1~50으로 줄어들었으니 다시 중간값(25) 업다운을 물어봄 -> 30은 25를 넘으니 업 하면 -> 25~50 으로 범위 줄어듦
- 이처럼 경우의 수를 반으로 줄여가면서.... 최악의 경우 남은 숫자가 2개 남을때 까지 업다운 후 둘중의 하나 고르면 끝
여기서 핵심은 연산을 하는 도중에 연산횟수(연산범위)가 줄어든다는 것이다.
만약 그냥 1~100까지 수 중에 이진탐색을 안하고 1이에요? 2예요? 3이에요? 하나하나 물어보면 나이가 80살이면 80번 물어봐야 할 것이다.(시간복잡도 O(n))
위에서는 반씩 줄여가기 때문에 그보다 훨씩 적은 횟수만 연산해서 원하는 값을 도출 가능하다. (O(log n))
4. O(n^2)
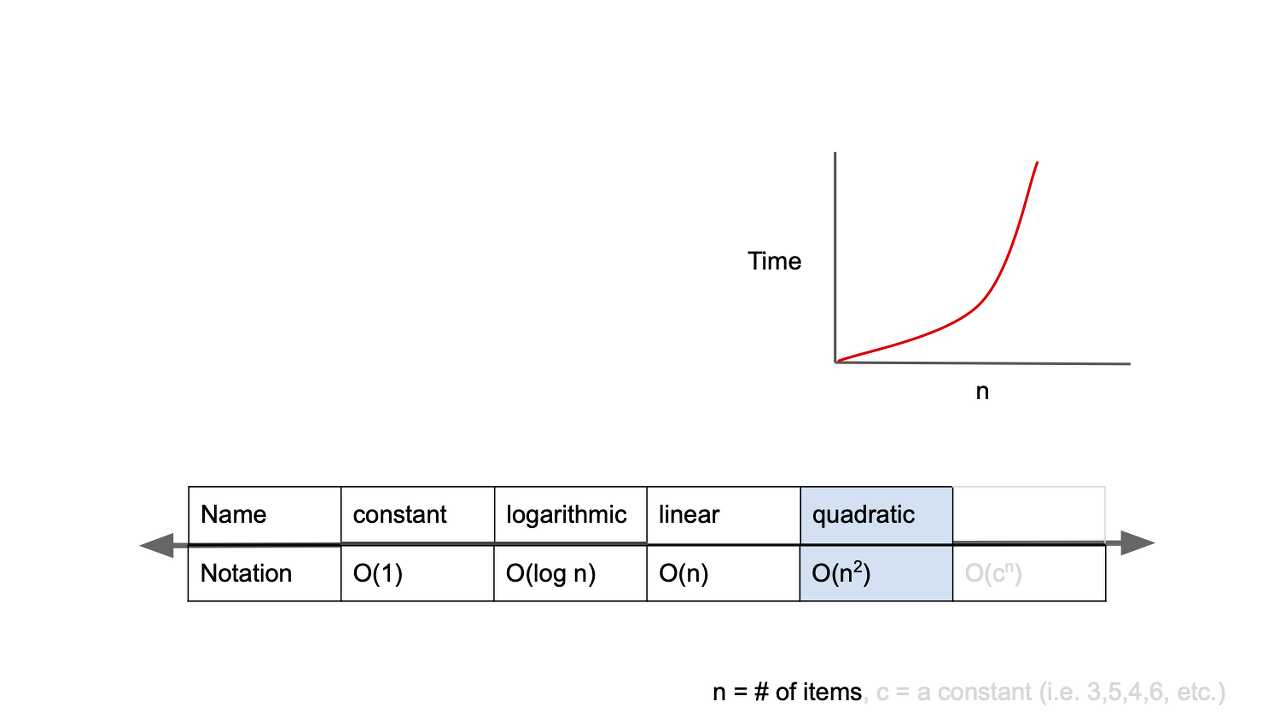
시간복잡도 O(n^2)는 입력값이 증가하면 연산시간이 n의 제곱수의 비율로 증하가는 경우다.
만약 1초 걸리던 알고리즘에 5를 넣었는데, 25초 (입력값 5^2초)가 걸린다면 O(n^2)의 시간복잡도를 가지는 알고리즘이라는 것이다.
뭔지 모르겠다고?
가장 대표적인 예시가 이중 for문이다.
코드예시
public void O_quadratic_N(int n) {
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
System.out.println(i);
}
}
}위의 코드에서 이중 for문으로, 같은 연산이 n*n번 돌게 되어 있다.
(안쪽의 for문이 다 돌면, 바깓의 for문의 i값이 1 올라가고 또 안쪽의 for문을 돌린다. )
이처럼, 입력값(n)이 증가함에 따라 n*n(n^2)형태를 띄는 알고리즘의 시간복잡도를 O(n^2)라고 한다.
그런데, 이중 for문 말고 또 하나 더 넣어서 삼중으로 만들면 O(n^3)이네? 라고 생각 할 수 있다.
코드예시
public void another_O_quadratic_algorithm(int n) {
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
for(int k = 0; k < n; k++) {
// do something for 1 second
}
}
}
}앞에서 O(n) 시간 복잡도를 내부에 상관 없이 (O(n), O(2n) 상관 없이) 다 O(n)라고 부르는 것 처럼, O(n^3)인 경우도 O(n^2)로 부른다.
"얼마나 시간이 늘어나냐" 가 중요한것이 아니라, "어떤식으로 늘어나느냐(어떤 구조로 늘어나느냐)"가 시간복잡도 분류의 핵심이다.
5. O(2^n)

시간복잡도 O(2^n)은 시간복잡도 중에서 가장 느린 복잡도를 가진다.(연산 시간이 제일 길다.)
데이터가 늘어날수록 연산시간이 기하급수적으로 늘어나는 형태로 마치 발산하는듯한 형태이다.
가장 대표적인 예로 피보나치를 재귀함수로 구현한 예시가 있다.
코드 예시
public int fibonacci(int n) {
if(n <= 1) {
return 1;
}
return fibonacci(n - 1) + fibonacci (n - 2);
}n이 증가하면 작동되는 재귀함수는 기하급수적으로 늘어난다.
n이 40이여도 수 초가 걸리고 100이면 평생 결과를 반환받지 못할 수도 있다고 한다.
코딩테스트에서 시간복잡도를 정하는 팁
입력으로 주어지는 데이터 크기를 잘 보면 된다.
만약 통상적인 100~1000 정도의 혹은 그보다 조금 더 입력 데이터가 들어온다면 O(n)으로 시간복잡도를 설정하고 그에 맞게 코딩을 진행하면된다.
하지만 100000000처럼 엄청 큰 데이터는 분명 시간복잡도O(n)으로 하면 채점 기준 중 일정 시간 오버가 되어 틀렷다고 나올 것이다.
여기서 우리는 O(log n)시간복잡도를 목표로 코드를 작성하여 해결해야 한다는것을 알아채야 한다.
핵심은 "주어진 데이터 수에 따라 목표로 하는 시간복잡도를 달리해야 한다."
데이터가 고만고만, 혹은 작으면 : O(n)
데이터가 무진장 크면 : O(log n)
4. 탐욕 알고리즘 (Greedy)
Greedy는 직역하면 "탐욕스러운, 욕심이 많은"이라는 뜻이다.
탐욕 알고리즘(Greedy Algorithm)은 당장 퇴적의 상황만을 채택하여 최종적인 결과를 내는 알고리즘이다.
탐욕 알고리즘으로 문제를 해결하는 방법으로는 다음과 같이 3 단계가 있다.
- 선택 절차 : 현제 상태에서 최적의 해답을 선택
- 적절성 검사 : 선택된 값이 문제의 조건을 만족하는지 검사
- 해답 검사 : 원래 문제가 해결되었는지 검사, 미해결 시 선택 절차(1번)으로 돌아가 위의 과정을 반복
글로 쓰니까 모르겠는데? 할 수 있다.
사실 우리가 실생활에서 그리드 알고리즘은 종종 사용했다.
바로 동전 거슬러 줄때 사용한다.
편의점에서 일하든, 마트에서 일하든 거스름돈을 줄 때 가장 적은 동전을 활용해 잔돈을 지불해야 나중에 동전이 부족하지 않다.
예를 들어서 만원으로 4320원 짜리 물건을 사서 5680원을 거슬러 줄 때
거스름돈 이하의 화폐중에서 가장 큰 단위 - 5천원
가장 큰 단위를 뺀 나머지 - 680원 (5천원 한장)
또 남은 거스름돈 이하의 화폐 중에서 가장 큰 단위 - 500원
가장 큰 단위를 뺀 나머지 - 180원 (500원짜리 하나)
또또 남은 거스름돈 이하의 화폐 중에서 가장 큰 단위 - 100원
가장 큰 단위를 뺀 나머지 - 80원 (100원짜리 하나)
또또또 남은 거스름돈 이하의 화폐 중에서 가장 큰 단위 - 50원
가장 큰 단위를 뺀 나머지 - 30원 (50원짜리 하나)
또또또또 남은 거스름돈 이하의 화폐 중에서 가장 큰 단위 - 10원
나머지 30원은 10원짜리 3개로 해결
총 5천원 한장 , 500원 하나, 100원 하나, 50원 하나, 10원짜리 3개로 해결!
-> 가장 적은 짤짤이로 거스름돈에 맞추었다.
여기서 위의 3 단계를 대입하여 말하면
선택 절차 : 가장 큰 단위의 화폐를 선택
(적은 화폐의 갯수로 조건을 충족시키기 위해) / 5천원부터 사용
적절성 검사 : 내가 선택한 화폐가 거스름돈을 넘지 않는지 검사
(5천원 2장은 거스름돈을 넘고, 한장은 안넘으니까 한장 주고 밑의 단위 화폐로 줘야 함)
해답검사 : 선택된 화폐들의 합이 거스름돈을 넘어가는지 검사하고, (5천원, 500원, 100원 ... 짤짤이 다 합해서) 넘으면 다시 처음부터 다시, 딱 맞으면 끝 -> 거스름돈을 올바르게 줫는지 검사한 것
그런데, 만약 10원짜리가 딱 하나 있어서 하나 밖에 쓸 수 없다면?
우리는 거스름돈 5680원 중 5660원으로 20원 부족하게 거슬러 주거나
50원짜리를 하나 더 써서 5710원으로 30원 더 주어야 한다.
-> 최적의 값으로 줄 수 없다!
이러한 상황이 발생 하기 때문에 탐욕 알고리즘을 적용하기위해서는 두 가지 조건이 따라 붙어야 최적의 값이 나온다.
- 탐욕적 선택 속성 : 앞의 선택이 이후의 선택에 영향을 주지 않아야 함
- 최적 부분 구조 : 문제에 대한 최종 해결 방법은 부분 문제에 대한 최적 문제 해결방법으로 구성됨
(마지막 10원짜리로 해결 가능한 부분인데(부분적 문제), 하나밖에 없으면 -> 해결 안됨, 그런데 여러개 있으면 10원짜리 여러개 주는거로 해결 가능 -> 부분적 문제 해결 가능)
위의 두 조건을 만족하지 않으면 탐욕 알고리즘은 최적의 답을 구하는데 적합하지 않다.
하지만, "최적(5680원)"이 아닌 것이지, "최적에 가까운 (5660원, 5710원)"값을 구할때는 빠르게 구할 수 잇는 알고리즘이 될 수 있다.
이러한 특성으로 탐욕 알고리즘은 근사 알고리즘으로 사용할 수 있다.
5. 구현 / 시뮬레이션
우리가 코딩테스트를 볼 때 유형 중에 구현, 시뮬레이션 유형이 있다.
일단, 알고리즘을 푼다는 것은 근본적으로 "내가 이 문제를 내가 생각반 방식대로 프로그래밍으로 구현 할 수 있다."를 보여주는 것이다.
일단 뭐든지 목표기능을 구현하는 코딩테스트를 출체 하는목적은
"본인이 선택한 프로그래밍 언어의 문법을 정확히 알고 있어야 하고, 문제 요건에 부합하는 코드를 빠르게 작성하는것"이 목표이다.
뭔소리냐고?
그냥 하나 오래걸리거나, 조건 많은거 던져 두고 그거 만들게 시킨다 이말이다.
그런데, 조건이 많아서 이것저것 문법을 사용해야 한다거나, 코드 길이가 줄줄줄길어져서 말 그대로 빡 구현을 해야 한다 이말이다.
구현/ 시뮬레이션 문제는 코딩체스트 지문을 잘 읽고 놓치는 조건없이 모두 코드로 구현하는것이 최우선 목표이다.
시뮬레이션 문제는 과정과 조건이 제시되는데, 해당 과정ㅇ을 거친 결과가 무엇인지 확인하게 되는 유형이다.
보통 문제에서 제시한 조건대로 코드를 작성하면 문제가 해결 되지만, 길고, 조건이 세세하게 많아서 코드로 치는게 쉬운일이 아닐 수 있다.
구현 / 시뮬레이션 문제는 "자주 연습해서 익숙해지는 것" 이외에는 딱히 방도가 없다.
적어도 for문이나 재귀함수 등 개념을 꽉 잡고 있어서 떠오른 아이디어에 바로 적용 할수 있어야 한다 이런 말이다.
구현 문제 예시로, 우리가 만약 조이스틱을 만든다고 하자.
왼쪽키를 누르면, 왼쪽으로, 오른쪽을 누르면 오른쪽, 아래를 누르면 아래로.....
단순 이동부터 메뉴 , 설정을 여는 키, 점프키 등등 다른 기능을 조건에 따라 하나 하나 만들어 주어야 한다는 것이다.
우리는 이 과정에서 (이렇게많은 것들을 구현해야 하는 과정에서)스스로 길을 잃지 않도록 주의히고, 자주 연습해서 정답을 내야 한다는 것이다.
솔직히, 알고리즘이 어렵고, 구현하기 까다롭고, 기타 등등의 문제가 있을 수 있다.
하지만 구현은 자신의 연습량 문제라고 생각한다.
코딩테스트 5문제면 적어도 1~2문제는 구현이라고도 한다.
열심히 해서 1~2문제는 꼭 맞을 수 있는 사람이 되자
6. 완전 탐색 알고리즘 (부르트포스 / Brute-Force Algorithm)
부르트포스 알고리즘은 단순하게 특정 값을 구하기 위해 가능한 값을 처음부터 끝까지 다 넣는것이라고 보면 된다.
예를들어 자물쇠 번호를 잊어버렸을 때, 자물쇠 버튼을 000~999까지 눌러보면서 맞는 숫자 나올때 까지 돌리는 것과 비슷하다.
자물쇠 버튼 누르는건 내 손의 빠르기에 달려있는 것 처럼, 부르트 포스 알고리즘은 컴퓨터의 성능에 달려 있다.
모든 가능성을 시도해서 답을 찾아내는 것이기 때문에 공간복잡도(알고리즘 구현하는데 사용되는 메모리 크기)와 시간 복잡도를 신경쓰지 않는다.
부르트포스를 쓰는 이유는 앞서 특정한 값을 찾거나 할 때 최악의 경우의 수시행 하더라도 답을 찾기 위해 사용된다.
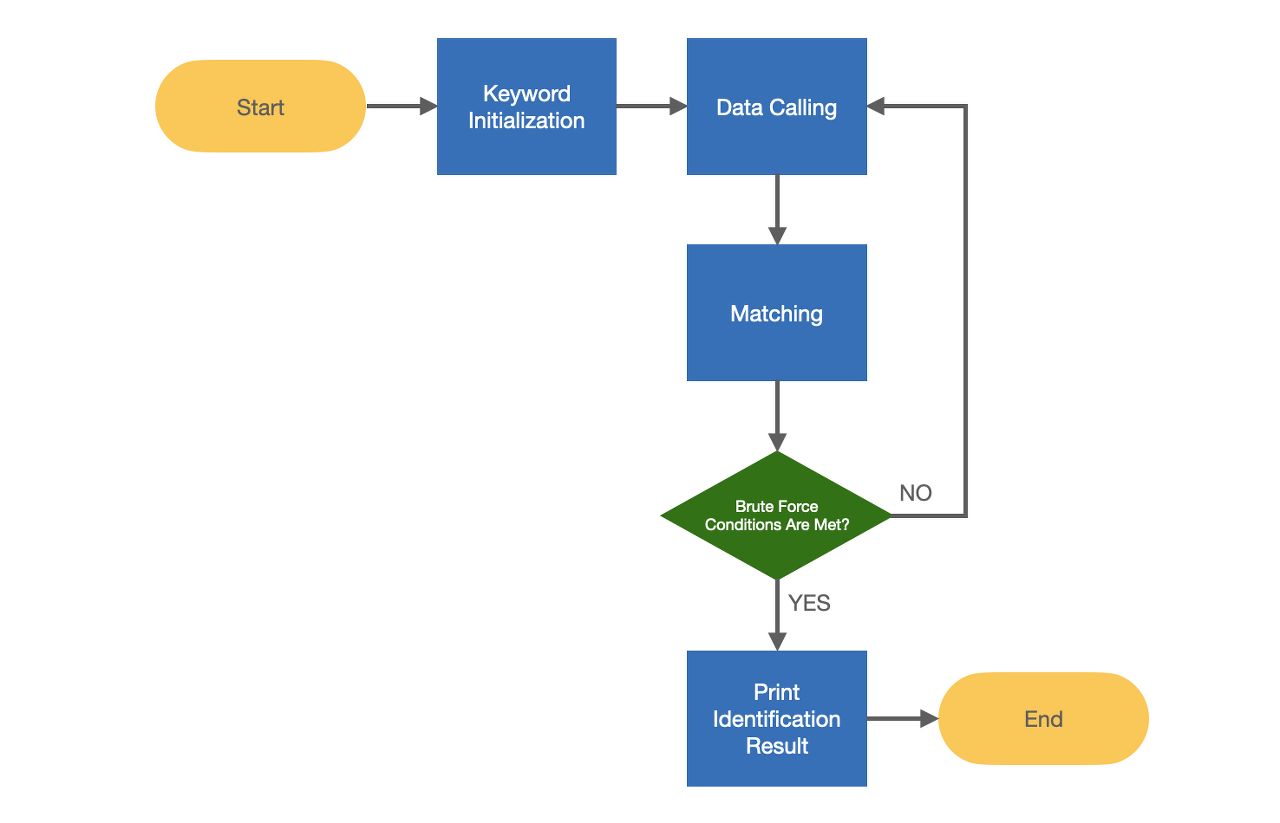
부르트포스는 크게 두가지 경우에 사용된다.
- 프로세스 속도를 높이는데 사용할 수 있는 다른 알고리즘이 없을 때
(직접 일일히 넣는거 말고 답 없을때) - 문제를 해결하는 솔루션이 여러개 있을 때 이 솔루션을 일일히 확인할 때
부르트포스는 하나하나 일일히 값을 넣어보면서 계속 연산을 하는것이므로, 문제의 목잡도에 치명적인 단점이 있다.
시간복잡도 O(n) , O(log n)은 그나마 나은데, O(n) , O(n^2) , O(2^n) 의 복잡도를 가진 경우, 데이터 범위가 넓어지는 순간부터 연산 시간은 기하급수적으로 늘어난다.
일반적으로, 내 컴퓨터 자원(메모리, 프로세스 속도)가 커버 가능하면 부르트 포스를 사용해도 된다, 하지만 불가능 할 경우 다른 알고리즘을 채택하여 다소 정확도가 떨어지더라도 효율성을 보장해야 한다.
7. 이진 탐색 알고리즘 (Binary Search Algorithm)
우리가 특정 값을 찾을 때 자료를 확인해서 특정 값에 도달하는것을 탐색이라고 한다.
만약 임의의 숫자를 지정해 놓고 찾으라고 한다면, 0부터 1, 2, 3..... 순으로 계속 확인 한다고 하자
이 경우 통상적인 숫자 (적당한 숫자, 100 이하라고 하자) 인 경우 금방 답이 나오겠지만, 높은 숫자 (100000....)의 경우에는 굉장히 오랜 시간이 걸릴 것이다.
탐색 알고리즘은 특정 값을 찾는데 걸리는 시간을 줄이면서 우리가 원하는 값을 내놓기 위해 만들어졌다.
이진 탐색 알고리즘은 앞에서 예를 든 숫자 업다운 과 동일하다고 보면 된다.
만약 5~200까지 숫자 중 182를 찾는 경우라고 생각해 보자

위의 그림에서 5~200 범위의 숫자 중 182의 숫자를 찾아내는 예시이다. (그림의 간략화를 위해 중간수는 많이 생략)
- 마치 업 다운 게임을 하는 것 처럼 찾고자 하는 범위를 반으로 나누어서 내가 차는 숫자보다 낮으면 제외시킨다
-> 탐색범위를 반으로 줄임 - 또 남은 범위에서 중간값 기준으로 내가 찾아햐 하는 숫자보다 적은 범위는 제외
-> 또또 탐색범위를 반으로 줄임 - 이를 반복해서 중앙값이 182로 딱 떨어지거나, 숫자가 2개 남는 순간 찾고자 하는 값이 나오게 된다.
결국 연산할수록 범위가 계속 줄어들기 때문에 O(log n)의 시간복잡도를 가지는 알고리즘이 된다.
이진탐색은 생각보다 많은 곳에 사용된다고 한다.
- 사전 탐색 : 사전에서 단어 찾을때
- 도서관 장서 검색 : 도서 청구기호로 책 찾을때
- 대규모 시스템에 대한 리소스 사항 파악 : 시스템 부하 테스트에서 예측된 부하를 처리하는데 필요한 CPU양을 파악할때 사용
- ADC : 아날로그 신호값을 디지털로 만들 때 사용
오늘은알고리즘에대해 개념만 쓰고 넘어갓다.
일단 내용파악이 우선이라서 최대한 내가 다시 풀어서 써봣는데 잘 된건지는 모르겟다.
사실 개념 아는것도 중요한데 코테를 위한것이니 직접 풀어보면서 익혀야 한다.
고로, 코드 예제 등을 쓰는 것 보다 나중에 자바 코딩 문제 풀이 등을 포스팅 하는것이 낫다고 판단하여 개념만 썻다 ㅎ
저~얼때 쓰기 귀찮은게 아니다.
사실 오늘은 왠지 공부 하기 싫어서 아주 몸을 비틀어가면서 포스팅을 작성햇는데 왜인지는 모르겠다
속도 별로 안좋고 뭔가 멀미나는 느낌도 들고... 일단 지금 잠깐 쉬어야겟다.
'백엔드 > 코드스테이츠 수강' 카테고리의 다른 글
| 코드스테이츠 수강_7주차_5일차_웹 애플리케이션 작동원리 (0) | 2022.09.30 |
|---|---|
| 코드스테이츠 수강_7주차_4일차_코딩테스트 준비(순열 / 조합) (0) | 2022.09.29 |
| 코드스테이츠 수강_7주차_1일차_자료구조, 탐색 알고리즘(Binary Search Tree, Search Algorithm(BFS, DFS)) (0) | 2022.09.26 |
| 코드스테이츠 수강_6주차_5일차_자료구조(Tree, Graph) (1) | 2022.09.23 |
| 코드스테이츠 수강_6주차_4일차_자료구조(Stack, Queue) (1) | 2022.09.22 |