코드스테이츠 수강 5주차 3일차에는 스레드, 자바 가상머신에 대해 배웟다.
1.스레드
우리가 PC 사용할 때, 카톡도 하고, 유튜브로 노래들으면서 코딩할 수 있는게 이 쓰레드 덕분이다.
스레드는 데이터와 어플리케이션이 확보한 자원을 활용하여 소스코드를 실행하는 것이다.
프로그램이 동작하는 것은 프로세스라고 하는데, 이 프로세스들을 한번에 여러개 돌리려면 여러개의 스레드가 필요하다.

물론, 하나의 프로세스에 여러개의 스레드가 사용 될 수 있다.
하나의 프로세스에 한개의 스레드가 사용되면 싱글 스레드 프로세스 , 여러개가 필요하면 멀티스레드 프로세스 라고 한다.
쉽게 말하면 실행중인 애플리캐이션(앱) 은 프로세스, 프로세스 내에서 실행되는 소스코드의 실행 흐름은 스레드라고 한다.
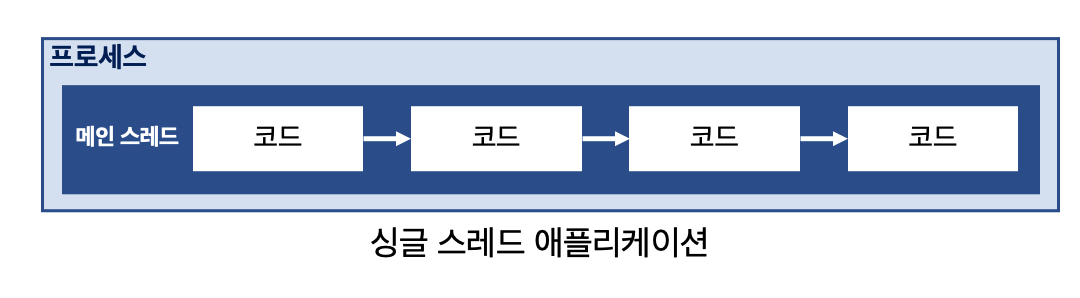
메인 스레드
우리가 자바 어플리캐이션을 실행하면 가장 먼저 실행되는 메서드는 main 메서드인데, 메인 스레드가 main 메서드를 실행시키는 것이다.
우리가 평소 사용하는 것처럼 메인 스레드는 main 메서드의 코드를 처으무터 끝가지, 혹은 return 까지 동작 후 종료한다.
따로 스레드를 생성하지 않은 이상 메인 스레드가 동작하고, 싱슬 스레드로 동작한다.
멀티 스레드
위에서 말한 것과 같이 하나의 프로세스가 여러개의 스레드를 가질 수 있는데, 이를 멀티 스레드 프로세스라고 한다.
여러개의 스레드를 가진다는 것은 여러 스레드가 동시에 작업을 수행할 수 있다는 것이고, 이를 멀티 스레딩이라고 한다.
멀티스레딩은 하나의 애플리케이션에서 여러작업을 동시에 수행하도록 하는데 핵심적이다.
예를 들어, 카카오톡을 사용하는데 사진을 보내면서 동시에 메세지를 주고받는것이 이 경우에 속한다.

멀티 스레드의 핵심 : 여러가지 작업을 동시에 수행 할 수 있다!!
작업 스레드의 생성과 실행
앞에서 말한 메인스레드 외에 별도의 작업 스레드를 활용한다는 것은, 작업 스레드가 수행할 코드를 작성하고, 생성시켜 실행한다는 것이다. (메인 이외에 다른 스레드 더 만든다는 뜻)
스레드가 수행할 코드는 run()메서드 안에 넣어주어야 한다.
(run()메서드는 이미 정의되어있다. 스레드가 처리할 작업을 작성하도록 규정되어 있다.)
run()메서드는 Runnable 인터페이스와 Thread 클래스에 정의되어져 있기 때문에, 작업 스레드를 생성하고 실행하는 방법은 두가지다.
1. Runnable 인터페이스를 구현한 객체에서 run()을 구현하여 스레드를 생성하고 실행하는 방법
코드예시
public class ThreadExample1 {
public static void main(String[] args) {
Runnable task1 = new ThreadTask1();
Thread thread1 = new Thread(task1);
// 작업 스레드를 실행시켜, run() 내부의 코드를 처리하도록 합니다.
thread1.start();
}
}
class ThreadTask1 implements Runnable {
public void run() {
for (int i = 0; i < 100; i++) {
System.out.print("#");
}
}
}위의 코드를 보면 Runnable 인터페이스를 구현한 객체(ThreadTask1)에서 run()메서드 안에 실행할 코드를 작성하였다.(이 부분을 새로 만들어지는 스레드가 실행하게 된다.)
이후 main에서 스레드를 생성하여 start()메서드를 사용하여 스레드를 동작시킨다.
2. Thread 클래스를 상속 받은 하위 클래스에서 run()을 구현하여 스레드를 생성하고 실행하는 방법
코드예시
public class ThreadExample2 {
public static void main(String[] args) {
ThreadTask2 thread2 = new ThreadTask2();
// 작업 스레드를 실행시켜, run() 내부의 코드를 처리하도록 합니다.
thread2.start();
// 반복문 추가
for (int i = 0; i < 100; i++) {
System.out.print("@");
}
}
}
class ThreadTask2 extends Thread {
public void run() {
for (int i = 0; i < 100; i++) {
System.out.print("#");
}
}
}
이 방법도 사실 Thread클래스를 상속받은것 이외에 차이가 없다.
다만, 인터페이스와 다르게 클래스를 통한 인스턴스 생성부분이 다른 것 뿐이다.
다만, 유심히 봐야 하는 부분이 있는데, main 스레드와 우리가 만들어준 스레드를 동시에 총 2개 실행하는것인데, 이렇게 되면 어떻게 나오느냐?

위의 사진처럼 지멋대로 나오는데, 우리가 뭘 정해준것도 아니고, 그냥 각자 동시에 작업을 하라고 시켯으니 코드를 실행하는대로 출력하는것이다. (첫번째로 작성한 Runnable에서도 동일하게 적용된다.)
스레드 동기화
앞에서 동시에 여러 스레드가 작업하면 코드를 실행하는 대로 출력하게 할 수 있는데, 이게 출력을 보면 지멋대로 쥬루룩 나온다.
만약 위에서처럼 단순 출력이 아닌, 변수 등을 공유하는 경우에는 어떤 스레드가 언제 얼마만큼의 변화를 줄 지 몰라 더 개판날수 있다.
이를 방지하기 위해 스레드 동기화가 필요하다.
코드 예시
public class ThreadExample3 {
public static void main(String[] args) {
Runnable threadTask3 = new ThreadTask3();
Thread thread3_1 = new Thread(threadTask3);
Thread thread3_2 = new Thread(threadTask3);
thread3_1.setName("kim coding");
thread3_2.setName("park java");
thread3_1.start();
thread3_2.start();
}
}
class Account{
private int balance = 1000;
public int getBalance(){
return balance;
}
public boolean withdraw(int money){
if(balance >=money){
try{Thread.sleep(1000);}catch (Exception error){}
balance -= money;
return true;
}
return false;
}
}
class ThreadTask3 implements Runnable{
Account account = new Account();
public void run(){
while (account.getBalance() > 0){
int money = (int)(Math.random() * 3 + 1 )*100;
boolean denied = !account.withdraw(money);
System.out.println(String.format("Withdraw %d won By %s, Balance : %d %s " , money , Thread.currentThread().getName(), account.getBalance(), denied ? "-> DENIED" : ""));
}
}
}위의 코드는 2명의 통장 출력 내역을 간단히 구현한 코드이다.
이용자 한명당 한 스레드를 배정해서 100~300원 단위로 1000원 있는 통장에서 돈을 빼는 것이다.
계속 돈을 빼서 빼고자 하는 돈보다 가진돈이 적으면 DENIED를 출력한다.
그런데 출력을 보면 뭔가 이상하다.

초반에 100원씩 빼다가 한번 300원을 뺐는데 갑자기 잔여금액이 300원이 되엇다. (1000 - 100 - 100 - 300 = 500이 맞는 셈이다.)
그 후로도 0이하로 떨어져도 DENIED를 출력하지 않고 지멋대로 마이너스통장으로 만들었다.
이게 바로 이전에 말한 두 스레드가 같은 객체가 공유되어 (같은 변수가 공유되어) 발생하는 오류다.
어떤 타이밍에 얼마를 반영하는지 서로 합의를 안했고, 마이너스통장으로 만들어 버렷다.
마이너스 통장이 된 이유도, if문으로 입금되어 있는 금액보다 출금금액이 크면 DENIED를 해야 하는데, if조건식을 평가해서 실행문으로 이동하는 타이밍에 다른 스레드가 그 변수를 사용하고, 지멋대로 balance를 사용해서 이런일이 벌어졋다.
이를 방지하기 위해 스레드 동기화가 필요하고, 이를 이해하려면 임계영역과 락이 필요하다.
임계 영역(Critical section)과 락(Lock)
임계 영역은 오로지 하나의 스레드만 코드를 실행할 수 있는 코드 영역을 의미하며, 락은 임계 영역을 포함하고 있는 객체에 접근할 수 있는 권한을 의미한다.
쉽게 말하면, 임계영역으로 객체를 지정해놓으면 락(Lock)을 획득한 스레드만 그 임계영역의 것들을 사용 할 수 있는것이다.
임계영역을 어떤 스레드가 사용하고 있으면 다른 스레들은 락(Lock)이 없으므로 임계영역을 사용 불가능 한 상태이므로 동시에 변수를 제멋대로 다루지 않는다.
임계영역을 사용하고 있던 스레드가 끝나서야 다른 스레드가 락을 가져가서 임계영역을 다룰 수 있다.
쉽게 비유하면 물품관리대장을 생각 하면 된다.

임계영역은 물품 관리대장에 쓸 수 있는 물품들이고, 락은 물품을 빌려가도 좋다는 일종의 허가 (관리 하는 사람의 ok 사인)과 같다고 보면 된다.
관리하는 사람이 안된다고 하면 물품을 못쓰는 것 처럼, 물품관리대장에서 목록화되지 않은 물품을 사용할 수 없는 것 처럼, 임계영역과 락이 이런 기능을 가진다.
"우리가 작성한 코드에서 그러면 어떻게 해야 하나?"
withdraw()메서드를 임계 영역으로 설정하면 된다. (balance 변수가 변하는 부분, if문을 통해 실행문에 이 부분이 있다. )
이걸 어떻게 하냐고?
지정하고자 하는 객체의 반환 타입 앞에 synchronized를 붙여주기만 하면 된다.
코드예시
public class ThreadExample3 {
public static void main(String[] args) {
Runnable threadTask3 = new ThreadTask3();
Thread thread3_1 = new Thread(threadTask3);
Thread thread3_2 = new Thread(threadTask3);
thread3_1.setName("kim coding");
thread3_2.setName("park java");
thread3_1.start();
thread3_2.start();
}
}
class Account{
private int balance = 1000;
public int getBalance(){
return balance;
}
public synchronized boolean withdraw(int money){
if(balance >=money){
try{Thread.sleep(1000);}catch (Exception error){}
balance -= money;
return true;
}
return false;
}
}
class ThreadTask3 implements Runnable{
Account account = new Account();
public void run(){
while (account.getBalance() > 0){
int money = (int)(Math.random() * 3 + 1 )*100;
boolean denied = !account.withdraw(money);
System.out.println(String.format("Withdraw %d won By %s, Balance : %d %s " , money , Thread.currentThread().getName(), account.getBalance(), denied ? "-> DENIED" : ""));
}
}
}Account 클래스 안의 withdraw 메서드의 반환 타입 앞에 synchronized를 붙임으로서 임계영역을 지정 할 수 있다.
이제 출력해보면

원금에서 빼는대로, 빼는 돈이 잔여금보다 많을 때 DENIED를 출력 하는 것을 볼 수 있다.
마이너스 통장(fi문, 그 안의 실행문이 씹히는것)도 없고 계산도 올바른 것을 볼 수 있다.
스레드의 상태와 실행 제어
위의 코드를 실습하면서, 스레드를 실행시키 위해 start() 메서드를 사용한 것을 볼 수 있다.
start()라서 "스레드를 실행시키는 거구나!" 할 수 있는데, 사실은 스레드를 실행 대기 상태로 만들어 주는 것이다.
스레드를 사용하는데에는 사실 여러가지의 상태가 있고, 이를 제어하는 메서드가 존재한다.

스레드 실행 제어 메서드
1. sleep(long milliSecond) : milliSecond 동안 스레드를 잠시 멈춤
sleep()은 스레드의 실행을 잠깐 멈추는데 사용한다.
sleep()의 괄호 안에는 밀리세컨드(m/s)단위로 숫자를 넣으면 그만큼 잠깐 멈췃다가 다시 시작한다.
실행 상태의 스레드에서 sleep()메서드가 실행되면 일시 정지(TIMES_WAITING) 상태가 된다.
sleep()으로 일시정시 상태가 되엇을때 다시 실행 되려면
- 지정한 시간이 경과한 경우
- intrerrupt()를 호출한 경우
interrupt()로 일시정지된 스레드를 실행대기로 만드려면 try, catch문을 사용해야 한다.(예외문을 작성해 주어야 한다.)
작성 예시
try { Thread.sleep(1000); } catch (Exception error) {}
2. interrupt() : 일시 중지 상태인 스레드를 실행 대기 상태로 복귀시킴
interrupt()는 sleep(), wait(), join()에 의해 일시 정지 된 스레드를 실행 대기 상태로 복귀 시키는데 사용된다.
interrupt()는 start()메서드 ㅊ럼 호출하여 사용되는데, 호출 한 순가 스레드의 상태가 실행대기로 전환된다.
작성예시
void interrupt()
인스턴스명.interrupt();위에서 try catch문으로 작성된 예시를 보면
try { Thread.sleep(1000); } catch (Exception error) {}try부분의 sleep으로 지정된 시간 도중에 interrupt가 들어오면, catch문 뒤의 중괄호 ( {} ) 안의 코드를 실행하고, 스레드는 실행 대기 상태가 되는 것이다.
3. yield() : 다른 스레드에게 실행을 양보
yield()는 다른 스레드에게 실행을 양보 할때 사용된다.
"양보? 뭔소리냐?" 싶을 수 있는데, 단순한 예시로, 목표로 하는 결과값이 나오면 그냥 다른 스레드를 실행시킬때 사용한다고 생각하면 된다.
만약, while문으로 1~100까지 하나하나 더하도록 스레드가 동작하게 만들었다고 하자.
예시
public void run() {
while (true) {
if (example) {
...
}
}
}예상으로는 한 3초 걸릴거 같아서 3초를 배정하고, 로직은 1+2+3+4.... 쮺쥭 100까지 더한다고 하자
그런데, 생각보다 빨리, 혹은 특정 조건에 의해서 원하는 결과값이 나왓을때 굳이 3초가 지날때 까지, 혹은 1~100가지 더할 필요가 없다!
그냥 결과값 나왓으니, 스레드를 종료하거나 다른놈이 놀게 양보하면 된다. (시간낭비, 자원낭비가 없어짐)
public void run() {
while (true) {
if (example) {
...
}
else Thread.yield();
}
}위의 코드처럼, 특정 조건에서 yield()메서드를 실행시킴으로 무의미한 작업을 줄일 수 있다.
4. join() : 다른 스레드의 작업이 끝날 때까지 기다림
join()은 특정 스레드가 작업하는 동안에 일시중시 상태로 만드는 메서드다.
sleep처럼 밀리세컨드(m/s)단위로 시간을 지정 할 수 있으먀, 시간이 경과하거나, 특정 스레드 동작이 끝나거나, interrupt()가 호출되면 실행대기 상태가 된다.
sleep()처럼 join()도 try catch문으로 감싸서 사용해야 한다.
하지만, sleep()과는 다르게 "특정 스레드"에 대해 동작하는 인스턴스 메서드이기 때문에 Thread클래스(자바에 정의되어 있는 클래스, 얘가 쓰레드를 상속시켜줘서 다른애들이 쓰레드 쓸 수 있게 함)를 호출해서 사용하지 않고, Thread 클래스로 생성된 "객체"에 호출해야한다.
- sleep()사용 시 : Thread.sleep(1000); // Thread클래스 가져와서 사용
- join() 사용 시 : thread1.join(); // Thread 클래스에서 생성된 객체를 가져와서 사용
5. wait(), notify() : 스레드 간 협업에 사용
둘 이상의 스레드가 동작할 때 사용
쉽게 말하면, 둘이서 번갈아 가면서 사용될때를 생각해 보자
위에서 스레드가 지들 멋대로 동시에 동작해서 개판이 나는데, 이거는 번갈아가면서 사용하는 것이다.
A 스레드, B스레드가 있다고 하자, A -> B -> A -> B ...이렇게 번갈아 실행된다고 가정하면
- A 스레드가 작업 후, 작업을 종료
- A 스레드가 움직이는게 다 끝나면 B스레드와 교대를 위해 notify()메서드 호출 하여 실행 대기 상태가 됨
- A 스레드는 B가 움직일때는 wait()을 호출하고 가만히 있음 (일시정지)
- B 스레드 작동
- 이후 B스레드가 작업이 종료되면, notify()메서드를 호출하여 A스레드를 실행 대기로 만듦
- B 스레드가 wait() 호출하고 가만히 있고(일시정지) A스레드가 실행됨
- 반복
방식은 위와 같고, 간단히 코드 예시만 넣어두겠다.
public class ThreadExample5 {
public static void main(String[] args) {
WorkObject sharedObject = new WorkObject();
ThreadA threadA = new ThreadA(sharedObject);
ThreadB threadB = new ThreadB(sharedObject);
threadA.start();
threadB.start();
}
}
class WorkObject {
public synchronized void methodA() {
System.out.println("ThreadA의 methodA Working");
notify();
try { wait(); } catch(Exception e) {}
}
public synchronized void methodB() {
System.out.println("ThreadB의 methodB Working");
notify();
try { wait(); } catch(Exception e) {}
}
}
class ThreadA extends Thread {
private WorkObject workObject;
public ThreadA(WorkObject workObject) {
this.workObject = workObject;
}
public void run() {
for(int i = 0; i < 10; i++) {
workObject.methodA();
}
}
}
class ThreadB extends Thread {
private WorkObject workObject;
public ThreadB(WorkObject workObject) {
this.workObject = workObject;
}
public void run() {
for(int i = 0; i < 10; i++) {
workObject.methodB();
}
}
}1. 자바 가상 머신
자바(java)의 대표적인 특징은 운영체제에 종속적이지 않다는 것이다.
이게 무슨말이냐? 하면
다른 언어 (C, C++)등은 운영체제에 종속적인데, 쉽게 말하면 윈도우에서 C,C++로 만든 애는 윈도우에서만 동작하고, MAC은 MAC에서만, 리눅스는 리눅스에서만 되는 것이다.
-> 운영체제가 달라지면 작동을 안한다. 운영체제에 맞게 새로 컴파일 해야 함
그런데 자바는 운영체제 상관없이 잘 작동 한다.
이유는 자바 가상머신(JVM) 덕분이다.
자바가 동작할 때 운영체제 위에서가 아닌, 가상머신 위에서 동작하기 때문에 운영체제와 상관 없는 것이다.

자바 가상머신(JVM)은 자바 프로그램을 실행시키는 프로그램이다.
자바로 작성한 소스코드를 실행하는 놈인 것이다.
원래, 프로그램이 실행되려면 CPU, 메모리 등등등 컴퓨터의 자원을 팔당 받아야 하는데, 이를 운영체제가 알아서 배정해 준다.
문제는 운영체제 마다 배정하는 방식이 달라서 이를 고려해서 일일히 컴파일 해야 한다는 것이다. (운영체제 종속성)
하지만 자바 가상머신은 자바 소스코드를 동작시키게 해주는 것으로, 운영체제와 소스코드 사이에서 일종의 통역을 해주는 것으로 운영체제와 상관 없이 작동 가능 한 것이다.
자바 가상머신도 윈도우용, MAC용, 리눅스용이 존재하기 때문에 개발환경에 따라 깔아주기만 하면 된다.
이해가 안되면 더 쉽게

다른놈들은 독자규격 단자라서 다른곳에 못꼳고 난리 나는데, 자바는 위 사진처럼 이곳저곳 꼳을 수 있게 젠더를 잘 만들어놔서 어디 호환 안된다 하는 이슈는 걱정 안해도 된다는 것이다.
JVM구조

위의 그림에서는 자바 코드를 실행하는 과정을 보여준다.
- 자바 소스코드를 작성 후, 컴파일 하여 .java file을 .class file(바이트 코드파일)로 변환한다.
- 이후 JVM은 운영체제로 부터 필요한 메모리를 할당받는다. (Rumtime Data Area영역)
- Class Loader 가 바이트 코드파일을 JVM내부로 불러와서 런타임 데이터 영역에 적재시킨다 -> 소스코드를 메모리에 로드한다.
- 로드가 완료되면 실행엔진(Execution Engine)이 런타임 데이터 영역에 적재된 코드를 실행시킨다.
이때 실행 엔진은 두가지 방식으로 코드를 실행시킨다. - 방식-1 인터프리터를 통해 코드를 한 줄씩 기계어로 번역하고 실행시키기
- 방식-2 JIT컴파일러를 통해 코드 전체를 기계어로 번역하고 실행시키기
기본적으로 방식-1을 사용하다가 자주 사용 되는 코드가 있으면 방식-2로 실행시킨다.
인터프리터는 짤짤이로 계속 일하고, JIT컴파일러는 자주 사용되는거 한번에 몰아서 처리
Stack과 Heap
Stack(스택)은 자료구조의 일종이다.
데이터 저장하는 방식중 하나다 이거다.
스택에 자료를 저장할 때 처음으로 넣은 데이터가 가장 마지막에 나오고, 마지막에 넣은 자료가 첫번째로 나온다.
뭔소리냐고? 탄창을 생각하면 쉽다.

탄창에 총알을 차곡차곡 넣고 가장 위에 적재된 총알부터 나가는 것 처럼, 스택도 가장 먼저넣은 데이터는 마지막까지 남고, 가장 최근에 넣은 데이터가 우선적으로 나온다.
(재밋는 사실 : 실제로 사이버전사 최고봉 북한은 Stack자료형을 탄창이라고 부른다. 실제로 Stack을 직역하면 탄창이다.)
JVM에서 Stack은 어찌동작하나?
메서드가 호출되면 그 메서드릉 위한 공간 Method Frame이 생성되는데, 이 안에는 매개변수, 참조변수 등등이 저장된다.
이Method Frame를 Strack 에 호출되는 순서대로 쌓아두고, 메서드의 동작이 끝나면 역순으로 짤짤이로 제거된다.

Heap 영역
JVM에는 단 하나의 Heap영역이 존재한다.
JVM이 작동될 때 Heap영역이 자동생성되는데, 이 안에 인스턴스 변수, 배열, 객체 등이 저장된다.
만약 우리가 인스턴스를 생성하면
Person person = new Person();new Person()이 실행되면, Heap영역에 인스턴스가 생성되고, 인스턴스가 생성된 위치의 주소값을 person에게 할당해준다.(참조변수)
이때, person은 Stack영역에 선언된 변수이다.
결론적으로 우리가 객체를 다룬다는것은 Stack영역에 저장되어 있는 참조변수를 통해 Heap 영역에 존재하는 객체를 다루는 것이다.
정리하면
- Heap : 객체의 실질적인 값 저장
- Stack : 객체의 주소 저장

Garbage Collection
Garbage Collection(가비지 컬렉션)? 쓰레기 모음집?
이게뭔가 싶겠지만, 말 그대로 쓰레기 모음집이다.
가비지 컬렉션은 메모리를 자동으로 관리해주는 프로세스인데, 프로그램에서 더 이상 사용하지 않는 객체를 찾아서 삭제하거나 제거하여 메모리를 확보한다.
코드 예시
Person person = new Person();
person.setName("황근출");
person = null;
// 가비지 발생
person = new Person();
person.setName("톤톤정");위의 코드를 보면, person 참조변수에 황근출 문자열을 가진 메모리를 참조변수 형태로 넣어두고 있다.
그런데, person을 null로 세팅하면 그 안의 데이터를 없애버린다!
그러면 person은 참조될 주소가 없는 상태이다.(메모리가 비엇다) -> 무의미한 객체가 된다.
이때 가비지 컬렉터가 person가 가지고 있던 메모리 점유를 헤제하게 된다.
->(메모리가 비엇고, 점유중인것들이 없어서, 사용가능한 공간이 된 상태)
후에, person을 다시 지정해서 톤톤정을 넣을 수 있게되었다.
가비지 컬렉터가 메모리 점유를 해제하엿기 때문에 해당 메모리 영역을 사용 할 수 있는 것이다!
가비지 컬렉션 동작방식
앞서 설명한 Heap 메모리 영역의 객체는 대부분 일회성이고, 메모리에 남아 있는 기간이 짧다.
그래서, 객체가 얼마나 살아있냐에 따라 Old, Young 영역으로 나눈다.
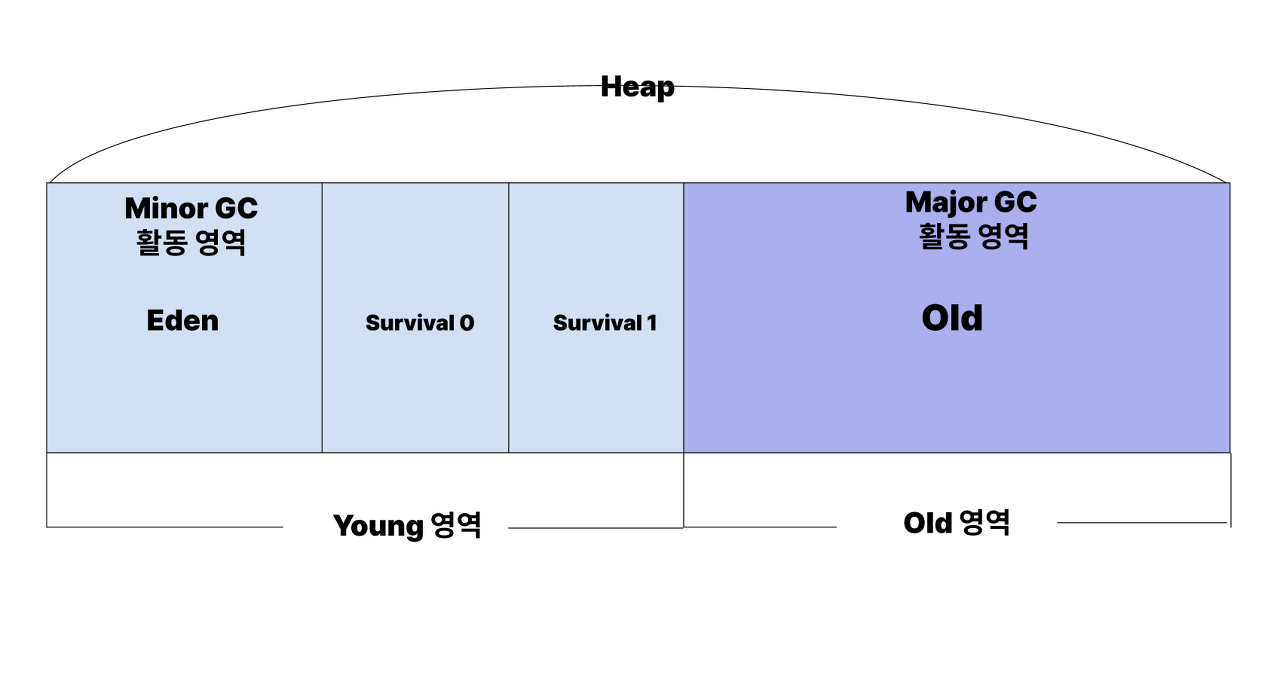
Young영역에서는 새롭게 생성된 객체가 달항되는 곳이고, 많은 객체가 여기서 생성되엇다가 사라지는것을 반복한다.
Young 영역에서 활동하는 가비지 컬렉터를 Minor GC(마이너 GC)라고 한다.
Old영역에서는 Young영역에서부터 살아남은 객체들이 복사되는 곳이다.
Young영역에 비해 크게 할단되고, 크기가 큰 만큼 가비지가 적게 발생한다.
Old영역에서 활동하는 가비지 컬렉터를 Major GC(메이저 GC)라고 한다.
Young, Old 영역에서의 가비지 컬렉션의 세부적인 동작은 다르지만, 기본적으로2가지 단계를 따른다.
- Stop The World
Stop The World는 가비지 컬렉션을 실행시키기 위해 JVM이 애플리케이션의 실행을 멈추는 작업이다.
가비지 컬렉션이 샐행될 때, 가비지 컬럭션을 실행하는 스레드 빼고 모든 스레드는 멈주고, 가비지 정리가 완료되면 재개한다.
잠깐 다 스톱하고 청소를 시작한다는 것이다.(모든 변수와 객체를 탐색해서 어떤 객체를 참고하는지 확인) - Mark and Sweep
Mark는 사용되는 메모리, 사용되지 않는 메모리를 식별하는 작업이다.
Sweep은 Mark단계에서 사용되지 않는 메모리라고 진단 된 메모리를 해제 하는 것이다.
청소할 것을 선별하고, 치워낸다는 것이다.
'백엔드 > 코드스테이츠 수강' 카테고리의 다른 글
| 코드스테이츠 수강_6주차_2~3일차_재귀함수 (1) | 2022.09.21 |
|---|---|
| [회고]코드스테이츠 수강_6주차_1일차_부트캠프 1달 경과 (1) | 2022.09.19 |
| 코드스테이츠 수강_5주차_2일차_JAVA_심화(애너테이션, 람다, 스트림, 파일 입출력) (0) | 2022.09.15 |
| 코드스테이츠 수강_5주차_1일차_JAVA_컬렉션(열거형, 제네릭, 예외 처리, 컬렉션 프레임워크) (0) | 2022.09.15 |
| 코드스테이츠 수강_4주차_3~4일차_JAVA_객체지향 프로그래밍 심화(다형성, 추상화) (1) | 2022.09.07 |